2021
General SQL Parser FAQ
Table of Contents
2020
Data lineage analysis from multiple SQL Files.
Data lineage analysis from multiple SQL Files and get accurate metadata result in JSON and CSV format.
SQL parse tree node and expression modification
A general review/summary of General SQL Parser: sql parser tree node and expression modification
SQL parse tree node and underlying tokens
A general review/summary of General SQL Parser: sql parser tree node and underlying tokens
SQL parse tree node and expression modification
A general review/summary of General SQL Parser: sql parser tree node and expression modification
SQL parse tree node and underlying tokens
A general review/summary of General SQL Parser: sql parser tree node and underlying tokens
Iterator interface implmented in TParseTreeNode and Iterable interface implmented in TParseTreeNodeList
Iterator interface implmented in TParseTreeNode is used to iterates the all source tokens of the parse tree node.
public abstract class TParseTreeNode implements Visitable,Iterator<TSourceToken>
Iterable interface implmented in TParseTreeNodeList is used to iterates all the parse tree nodes included in this list.
public class TParseTreeNodeList<T extends TParseTreeNode> extends TParseTreeNode implements Iterable<T>
Iterable interface implmented in TStatementList is used to iterates the all the sql statements included in this list.
public class TStatementList extends TParseTreeNode implements Iterable<TCustomSqlStatement>
Let take this SQL for example:
SELECT e.employee_id,
e.last_name,
e.department_id
FROM employees e,
departments d
;
SELECT e.employee_id,
e.last_name,
e.department_id
FROM employees e
JOIN departments d
ON e.department_id = d.department_id
Print the type of all sql statements:
for (TCustomSqlStatement sqlStatement:sqlparser.sqlstatements) {
System.out.println(sqlStatement.sqlstatementtype);
}
Since TParseTreeNodeList is subclass of TParseTreeNode, so TParseTreeNodeList support both Iterable and Iterator interface. Please aware that Iterator interface is used to get all source tokens belong to this node like this:
while(sqlStatement.tables.hasNext()){
System.out.println(sqlStatement.tables.next().toString());
}
While Iterable interface is used to get parse tree node in the list:
for(TTable table:sqlStatement.tables){
System.out.println(table.getTableType());
}
General SQL Parser and SQLFrog
GSP在SQLFrog项目中的应用
SQLFrog的两种工作模式
- scan模式,仅找出需要转换的SQL语法和语义,给出报告,不做转换。
- convert模式,找出需要转换的SQL语法和语义,并做转换。
scan为默认模式。
SQLFrog和GSP的关系
SQLFrog的底层实现依赖GSP的解析能力、visitor模式、语法树改动、语法树到SQL文本的生成技术。
使用GSP的visitor模式
顶层SQL语句应用某种类型node的visitor后,可以快速高效的访问语句中所有该类型的node。
下面这段代码示例访问所有TObjectName类型的node。在同一个visitor中,我们可以同时处理多个类型的node,根据实际的业务需求决定。
int ret = sqlparser.parse();
if (ret == 0){
objectNameVisitor objectNameVisitor = new objectNameVisitor();
for(int i=0;i<sqlparser.sqlstatements.size();i++){
TCustomSqlStatement sqlStatement = sqlparser.sqlstatements.get(i);
sqlStatement.acceptChildren(objectNameVisitor);
}
}
class objectNameVisitor extends TParseTreeVisitor {
public void preVisit(TObjectName node){
}
}
GSP的visitor对所有node的深度访问可能会有遗漏,在开发中遇到此类问题需及时反馈。
利用visitor来进行SQL语句中datatype的检查
例如,在netezza到snowflake的SQL转换过程中,我们需要检查datatype是否兼容,当发现create table语句中有使用ST_GEOMETRY datatype时, 我们就要标记出该datatype 需要被转换成snowflake的VARBINARY.
创建一个datatype visitor就非常容易实现以上功能。
class datatypeVisitor extends TParseTreeVisitor {
public void preVisit(TTypeName node){
// 加入功能检查代码
}
}
类似的,我们可以对SQL函数进行检查。
visitor配合GSP的语法树改动技术,进行SQL转换
当找到需要转换的语法或语义点后,需要进行转换,通过修改GSP生成的SQL语法树,我们可以做到这一点。GSP提供两种方法可以从语法树生成SQL文本:toString() and toScript()。
toString()
利用toString()从语法树生成SQL文本时,要求对语法树上node做改动时,必须对底层对应的token做好同步。
SQLFrog采用这种方法。
toScript()
利用toScript()从语法树生成SQL文本时,对语法树上node做改动,无需对底层对应的token做同步,但对语句中
的每一个node都要根据语法树重新生成文本,即便这个node在本次操作中没有发生变化。由于GSP目前无法对所有的SQL
语法都支持重新生成文本,因此容易导致生成不正确的SQL文本。
详细的说明可以看这篇文章。
还需要补充一篇文档对toString() and toScript()的工作原理做进一步的说明。
visitor相关代码
https://github.com/sqlparser/gsp_demo_java/tree/master/src/main/java/demos/visitors
SQL Function and TFunctionCall
SQL function 在GSP中用TFunctionCall类表示。所有的function都用这个类表示。
TFunctionCall中的基本信息
一般的SQL function的语法如下:
funcName(arg1,arg2)
TFunctionCall中对应属性值:
getFunctionName() = funcName
getArgs().size() = 2
getArgs().getExpression(0) = arg1
getArgs().getExpression(1) = arg2
getFunctionType() = unknown_t
目前 getFunctionType() 表示的函数类型并不完善,用它来判断函数并不一定准确,需小心。
不规则参数的函数
一般情况下,函数的参数由TExpressionList getArgs()获得,这些函数的参数形如:
funcName(arg1,arg2,arg3)
其中,arg1,arg2,arg3的类型都是表达式:TExpression。
但有一些函数的参数并不能仅仅由表达式来表示,例如cast函数,
SELECT CAST(ytd_sales AS CHAR(5)) FROM titles
除了ytd_sales可以用TExpression,还有AS关键字和CHAR(5)数据类型,所以cast函数
的参数不能用TExpressionList getArgs()获得,它对应的参数分别为:
getExpr1() = ytd_sales
getTypename() = CHAR(5)
函数的参数语法上的多样性,导致获取参数的API方式的不统一。以后API上可能需要改进以保证获取参数方法统一。
其它参数不规则的函数另行补充.
判断一个函数是否为数据库的内置函数(built-in funciton)
- 判断该函数是否为某一数据库的内置函数。
EDbVendor用来指定数据库厂商,例如db2,oracle等。public boolean isBuiltIn(EDbVendor pDBVendor) - 静态函数,需指定函数名。功能同1.
public static boolean isBuiltIn(String pName, EDbVendor pDBVendor)
aggregate function
1. ALL | DISTINCT
getAggregateType() is used to determine the ALL | DISTINCT used in the aggregate function.
2. WITHIN GROUP
This information is not available in the TFunctionCall yet.
window function
FUNCTION_NAME(expr) OVER {window_name | (window_specification)}
在Oracle and SQL Server中,window_specification也称为window_clause。
在GSP中,用TWindowDef表示window_specification, 在TFunctionCall中,用以下方法获得window_specification
public TWindowDef getWindowDef()
以这个包含window function的SQL为例:
SELECT NUM, ODD,
CUME_DIST( ) OVER(PARTITION BY ODD ORDER BY NUM) cumedist
FROM test4
GSP的输出为:
sstselect
--> function: CUME_DIST, type:unknown_t
window_specification
Parition value: ODD
Order by clause: NUM
CASE FUNCTION
用TCaseExpression表示。
Related demo
SQL Datatype and TTypeName
SQL Datatype and TTypeName
SQL的数据类型,GSP中的对应类:TTypeName。
SQL Datatype的类型
TTypeName 表示SQL中的数据类型,例如:
char(10),
int,
float(24),
decimal(8,2)
基本属性
以表示 decimal(8,2)为例,TTypeName的基本熟悉值如下:
getDataType() = decimal_t
toString() = decimal(8,2)
getDataTypeName() = decimal
扩展属性
扩展属性仅适用于部分特定的datatype。
getLength()
以 char(10)为例
getLength() = 10
getPrecision(), getScale()
以 decimal(8,2)为例
getPrecision() = 8
getScale() = 2
参考资料
SQL2003 datatypes 的详细列表见 “SQL in a Nutshell, 3rd Edition” p30, Table 2-8. SQL2003 categories and datatypes
Related demo
EDataType的完整列表
package gudusoft.gsqlparser;
/**
* @since v1.4.3.0
*/
public enum EDataType {
unknown_t,
/**
* user defined datetype
*/
generic_t,
bfile_t,
/**
* ansi2003: bigint
* postgresql
*/
bigint_t,
/**
* ansi2003: blob
*/
binary_t,
binary_float_t,
binary_double_t,
/**
* plsql binary_integer
*/
binary_integer_t,
/**
* binary large object
* Databases: DB2, teradata
*/
binary_large_object_t,
bit_t,
bit_varying_t, // = varbit
blob_t,
/**
* bool, boolean, ansi2003: boolean
*/
bool_t,
box_t,
/**
* teradata: byte
*/
byte_t,
bytea_t, //ansi2003 blob
/**
* teradata byteint
*/
byteint_t,
/**
* char, character, ansi2003: character
*/
character_t,
char_t,
char_for_bit_data_t,
/**
* teradata: character large object
*/
char_large_object_t,
cidr_t,
circle_t,
clob_t,
cursor_t,
datalink_t,
date_t,
/**
* ansi2003: timestamp
*/
datetime_t,
datetimeoffset_t,// ansi2003: timestamp
datetime2_t, // ansi2003: timestamp with time zone
/**
* ansi2003: nclob
* Databases: DB2
*/
dbclob_t,
/**
* dec,decimal, ansi2003: decimal
*/
decimal_t,
dec_t,
/**
* double, double precision, ansi2003: float
*/
double_t,
enum_t,
float_t,// ansi2003: double precision
float4_t,// ansi2003: float(p)
float8_t, // ansi2003 float(p)
/**
* ansi2003 blob
*/
graphic_t,
geography_t,
geometry_t,
hierarchyid_t,
image_t,
inet_t,
/**
* int, integer, ansi2003: integer
*/
integer_t,
int_t,
int2_t, // ansi2003: smallint
int4_t, // ansi2003: int, integer
/**
* Postgresql
*/
interval_t,
/**
* teradata: interval day
*/
interval_day_t,
/**
* teradata: interval day to hour
*/
interval_day_to_hour_t,
/**
* teradata: interval day to minute
*/
interval_day_to_minute_t,
interval_day_to_second_t,
/**
* teradata: interval hour
*/
interval_hour_t,
/**
* teradata: interval hour to minute
*/
interval_hour_to_minute_t,
/**
* teradata: interval hour to second
*/
interval_hour_to_second_t,
/**
* teradata: interval minute
*/
interval_minute_t,
/**
* teradata: interval minute to second
*/
interval_minute_to_second_t,
/**
* teradata: interval month
*/
interval_month_t,
/**
* teradata:interval second
*/
interval_second_t,
/**
* teradata interval year.
*/
interval_year_t,
interval_year_to_month_t,
line_t,
long_t,
long_varchar_t,
/**
* long varbinary, mysql
* MySQL Connector/ODBC defines BLOB values as LONGVARBINARY and TEXT values as LONGVARCHAR.
*/
long_varbinary_t,
longblob_t, // ansi2003: blob
/**
* ansi2003: blob
*/
long_raw_t,
long_vargraphic_t,
longtext_t,
lseg_t,
macaddr_t,
mediumblob_t,
/**
* mediumint, middleint(MySQL) , ansi2003: int
*/
mediumint_t,
mediumtext_t,
money_t, // = decimal(9,2),INFORMIX
/**
* national_char_varying,nchar_varying,nvarchar, ansi2003: national character varying
*/
nvarchar_t,
/**
* nchar, national char, national character,ansi2003: national character
*/
nchar_t,
ncharacter_t,
/**
* ansi2003: nclob
*/
nclob_t,
/**
* ntext, national text, ansi2003: nclob
*/
ntext_t,
/**
* nvarchar2(n)
*/
nvarchar2_t,
/**
* number, num
*/
number_t,
/**
* ansi2003: numeric
*/
numeric_t,
oid_t,
path_t,
/**
* teradata: period(n)
*/
period_t,
/**
* plsql pls_integer
*/
pls_integer_t,
point_t,
polygon_t,
raw_t,
/**
* ansi2003: real
*/
real_t,
rowid_t,
rowversion_t,
serial_t,// = serial4
serial8_t,// = bigserial
bigserial_t,//informix
smallfloat_t,//informix
/**
* MySQL: set
*/
set_t,
smalldatetime_t,
/**
* ansi2003: smallint
*/
smallint_t,
smallmoney_t,
sql_variant_t,
table_t,
text_t,
/**
* ansi2003: time
*/
time_t,
/**
* teradata: time with time zone
*/
time_with_time_zone_t,
time_without_time_zone_t,
timespan_t, // ansi2003: interval
timestamp_t, // ansi2003: timestamp
/**
* timestamp with local time zone,
* Database: Oracle,SQL Server
*/
timestamp_with_local_time_zone_t,
/**
* timestamp with time zone, timestamptz, ansi2003: timestamp with time zone
*/
timestamp_with_time_zone_t,
timestamp_without_time_zone_t,
/**
* time with time zone, ansi2003: time with time zone
* Databases: teradata
*/
timetz_t,
timentz_t,
tinyblob_t,
tinyint_t,
tinytext_t,
uniqueidentifier_t,
urowid_t,
/**
* ansi2003: blob
*/
varbinary_t,
/**
* netezza, bit varying
*/
varbit_t,
/**
* teradata: varbyte
*/
varbyte_t,
/**
* varchar, char varying, character varying, ansi2003:character varying(n)
*/
varchar_t,
/**
* ansi2003: character varying
*/
varchar2_t,
varchar_for_bit_data_t,// ansi2003: bit varying
lvarchar_t, //informix,openedge
idssecuritylabel_t,//informix
/**
* ansi2003: nchar varying
*/
vargraphic_t,
row_data_types_t, //informix
collection_data_types_collection_t,
collection_data_types_set_t,
collection_data_types_multiset_t,
collection_data_types_list_t,
/**
* ansi2003: tinyint
*/
/**
* datatypeAttribute in cast function will be treated as a datatype without typename
* RW_CAST ( expr AS datatypeAttribute )
*/
no_typename_t,
year_t,
xml_t, // ansi2003: xml
xmltype_t, // ansi2003: xml
natural_t, //plsql
naturaln_t,//plsql
positive_t,
positiven_t,
signtype_t,
simple_integer_t,
double_precision_t,
boolean_t,
string_t,
listType_t, //hive array <type>
structType_t,//hive
mapType_t,
unionType_t,
refcursor_t,//postgresql
json_t, //postgresql
jsonb_t,//postgresql
self_t,//oracle, constructor function
seconddate_t,//hana
smalldec_t,//hana
array_t,//hana,bigquery
alphanum_t,//hana
shorttext_t,//hana
bintext_t,//hana
currency_t,//dax
int8_t,
lvarbinary_t,//openedge
long_byte_t,//mysql
object_t,//snowflake
variant_t,//snowflake
unsigned_int_t,//
decfloat_t,//db2
struct_t,//bigquery
int64_t,//bigquery
float64_t,//bigquery
}
SQL Object and TObjectName
SQL Object and TObjectName类
数据库中的Object,例如table, column, view, schema, database 在ANSI SQL中用<identifier>表示。
<identifier>是一个字符串,最大长度为128个字符。
<regular identifier>
<regular identifier> ::=
Object name
<SQL language identifier>
<SQL language identifier> ::=
Object name
An <SQL language identifier> is a <regular identifier> that consists only of simple Latin letters, digits, and underscore characters. It must begin with a simple Latin letter.
<delimited identifier>
<delimited identifier> ::=
"Object name"
ANSI SQL中,<delimited identifier>用 double quote marks(双引号),而在SQL Server中,使用[ and ].
MySQL使用 `.
Qualification of <identifier>s
qualified object name, 是指几个identifier的组合,形成有层次结构的object name。
一般是
server.db.schema.table.column
SQL object name and TObjectName
在GSP中,用TObjectName表示SQL object name,用TSourceToken类表示identifier。
因此TObjectName 包含一个或多个TSourceToken,有下列可用的token:
public TSourceToken getMethodToken() -- 表示method
public TSourceToken getPartToken() -- 表示column
public TSourceToken getObjectToken() -- 表示 table,view, index等schema level的object
public TSourceToken getSchemaToken()
public TSourceToken getDatabaseToken()
public TSourceToken getServerToken()
Column
-
Only column name
select empNo from emp表示empNo column 的TObjectName中的各种值如下:
getDbObjectType() = column toString() = empNo getPartToken() = empNo -
qualified column name
select t.empNo from emp t表示empNo column 的TObjectName中的各种值如下:
getDbObjectType() = column toString() = t.empNo getPartToken() = empNo getObjectToken() = t
Table
- Only the table name
select empNo from emp表示emp table的TObjectName中的各种值如下:
getDbObjectType() = table toString() = emp getObjectToken() = emp - qualified table name with schema
select t.empNo from scott.emp t表示emp table的TObjectName中的各种值如下:
getDbObjectType() = table toString() = scott.emp getObjectToken() = emp getSchemaToken() = scott - qualified table name with database and schema
select t.empNo from hrdb.scott.emp t表示emp table的TObjectName中的各种值如下:
getDbObjectType() = table toString() = scott.emp getObjectToken() = emp getSchemaToken() = scott getDatabaseToken() = hrdb - qualified table name with server, database and schema
select t.empNo from server1.hrdb.scott.emp t表示emp table的TObjectName中的各种值如下:
getDbObjectType() = table toString() = scott.emp getObjectToken() = emp getSchemaToken() = scott getDatabaseToken() = hrdb getServerToken() = server1
Function
SELECT * FROM Department D
CROSS APPLY dbo.fn_GetAllEmployeeOfADepartment(D.DepartmentID)
表示fn_GetAllEmployeeOfADepartment function的TObjectName中的各种值如下:
getDbObjectType() = function
toString() = dbo.fn_GetAllEmployeeOfADepartment
getObjectToken() = fn_GetAllEmployeeOfADepartment
getSchemaToken() = dbo
Method
Method like nodes() of SQL Server xml Data Type.
select doc.c.value('level', 'int') as [Level]
from N.ReformattedSegments.nodes('/path/segment') doc(c)
表示N.ReformattedSegments.nodes method 的TObjectName中的各种值如下:
getDbObjectType() = method
toString() = N.ReformattedSegments.nodes
getMethodToken() = nodes
getPartToken() = ReformattedSegments
getObjectToken() = N
Related demo
SELECT and TSelectSqlStatement
SELECT 和 TSelectSqlStatement类
各种数据库中使用的SELECT语句, 在SQL ANSI中对应<query specifcation>,或更复杂的<query expression>。
我们常说的SUBQUERY,是<left paren> <query expression> <right paren>,代表从<query expression>衍生出来的一个标量、一行记录、或一个表。
一些基本的术语
1. table expression
<table expression>te1, Specify a table or a grouped table.
<table expression> ::=
<from clause>
[ <where clause> ]
[ <group by clause> ]
[ <having clause> ]
[ <window clause> ]
2. table reference
<table reference>tr1,tr2, Reference a table.
Since the result of a query is a Table derived by evaluating that query, not all SQL Tables have an explicit <Table name> – so SQL allows you to refer to any Table using a <Table reference>. (重点是SQL中的table不仅仅是数据库中存在的base table, 还有其它例如subquery, VALUES CLAUSE, function table等)。
<table reference> ::=
<table factor>
| <joined table>
<table factor> ::=
<table primary> [ <sample clause> ]
3. query specifcation
<query specifcation>qs1, Specify a table derived from the result of a <table expression>.
<query specification> ::=
SELECT [ <set quantifier> ] <select list> <table expression>
4. query expression
<query expression>qe1, Specify a table.
在<query specifcation>的基础上,支持<with clause>
和 SET OPERATOR(UNION,EXCEPT,INTERSECT),同时支持<table value constructor>,<explicit table>.
<query expression>用括号括起来后,可以用在SQL中任何需要Table的地方。
<query expression> ::=
[ <with clause> ] <query expression body>
<query expression body> ::=
<query term>
| <query expression body> UNION [ ALL | DISTINCT ]
[ <corresponding spec> ] <query term>
| <query expression body> EXCEPT [ ALL | DISTINCT ]
[ <corresponding spec> ] <query term>
<query term> ::=
<query primary>
| <query term> INTERSECT [ ALL | DISTINCT ] [ <corresponding spec> ] <query primary>
<query primary> ::=
<simple table>
| <left paren> <query expression body> <right paren>
<simple table> ::=
<query specification>
| <table value constructor>
| <explicit table>
5. subquery
<subquery>s1, Specify a scalar value, a row, or a table derived from a <query expression>.
<scalar subquery> ::=
<subquery>
<row subquery> ::=
<subquery>
<table subquery> ::=
<subquery>
<subquery> ::=
<left paren> <query expression> <right paren>
GSP 中的对应类
SQL语句在GSP中都有对应的类,其中对应<query expression>的是TSelectSqlStatement,TSelectSqlStatement也可以表示<query specification>,<table value constructor>及用SET OPERATOR连接的<query specification>。
1. TSelectSqlStatement表示<query specification>
这是最常见的用法,TSelectSqlStatement类的属性包含<table expression>的各个组成部分<from clause>,<where clause>,<group by clause>,<having clause>,<window clause>,也可以包含<with clause>。
2. TSelectSqlStatement表示 SET OPERATOR连接的<query specification>
这种情况下,只有TSelectSqlStatement getLeftStmt() and TSelectSqlStatement getRightStmt()可用,分别表示
SELECT boss_name, salary FROM Bosses
UNION
SELECT employee_name, salary FROM Employees;
中的
SELECT boss_name, salary FROM Bosses
SELECT employee_name, salary FROM Employees;
其中,getLeftStmt()表示的TSelectSqlStatement可以再次表示SET OPERATOR连接的<query specification>,形成递归。而getRightStmt()表示的TSelectSqlStatement只能是<query specification>。
public boolean isCombinedQuery()可以用来确定TSelectSqlStatement是否为SET OPERATOR连接。
3. TSelectSqlStatement表示<table value constructor>
<table value constructor>最长见的用法是在INSERT语句中,但也可以用在需要SELECT的地方。
这就是为什么<table value constructor>在GSP中是用TSelectSqlStatement类来表示的原因。
VALUES (’NEWAAA’, ’new’), (’NEWBBB’, ’new’)
因此,当我们处理表示<table value constructor>的TSelectSqlStatement类实例时,必须要小心,
因为很多SELECT语句中的元素这时在TSelectSqlStatement类实例中不存在,
访问这些类属性将会导致NullPointerException的错误。
isValueClause() 可以用来检查一个TSelectSqlStatement类是否表示<table value constructor>,如果是,用
TValueClause getValueClause()来获取进一步的详细内容。
Reference
- te1. ISO/IEC 9075-2 (SQL/Foundation) 2006. p318, 7.4
- tr1, ISO/IEC 9075-2 (SQL/Foundation) 2006. p321, 7.6
- tr2, crate-sql99.pdf, p462
- qs1, ISO/IEC 9075-2 (SQL/Foundation) 2006. p361, 7.12
- qe1, ISO/IEC 9075-2 (SQL/Foundation) 2006. p371, 7.13
- s1, ISO/IEC 9075-2 (SQL/Foundation) 2006. p390, 7.15
values-clause and TSelectSqlStatement
values-clause
Derives a result table by specifying the actual values, using expressions, for
each column of a row in the result table. Multiple rows may be specified.
SELECT EMPNO, ’emp_act’
FROM EMP_ACT
WHERE PROJNO IN(’MA2100’, ’MA2110’, ’MA2112’)
UNION
VALUES (’NEWAAA’, ’new’), (’NEWBBB’, ’new’)
values-clause最长见的用法是在INSERT语句中,但也可以用在需要SELECT语句的地方。
这就是为什么values-clause在GSP中是用TSelectSqlStatement类来表示的原因。
values-clause的语法构成和SELECT语句非常的不同,
VALUES (1),(2),(3)
因此,当我们处理表示values-clause的TSelectSqlStatement类实例时,必须要小心,
因为很多SELECT语句中的元素这时在TSelectSqlStatement类实例中不存在,
访问这些类属性将会导致NullPointerException的错误。
访问TSelectSqlStatement表示的values-clause
Use this method to get values-clause
public TValueClause getValueClause()
if the return value is not null, then this TSelectSqlStatement instance represents a values-clause.
Since GSP Java version 2.0.6.9(2020-06-18), TSelectSqlStatement.isValueClause() is added to help determine
whether a TSelectSqlStatement class represents a values-clause or not.
Overview of General SQL Parser - sql parse tree manipulation
A general review/summary of General SQL Parser: sql parser tree manipulation
Overview of General SQL Parser - sql parse tree to query
A general review/summary of General SQL Parser: sql parser tree to query
Overview of General SQL Parser - sql parse tree
A general review/summary of General SQL Parser: sql parser tree
Overview of General SQL Parser
A general review/summary of General SQL Parser
Overview of General SQL Parser
A general review/summary of General SQL Parser
Install and use the Genearl SQL Parser package using the dotnet CLI
Table of Contents
Duplicate column in create view
CREATE TABLE t1(f1 int , f3 int);
CREATE TABLE t2(f1 int , f3 int);
CREATE VIEW v1
as
SELECT
t1.f1, -- please note the column name will be f1 in v1
t2.f1, -- please note the column name will be f1 in v1
t1.f2, t2.f3
FROM t1, t2
WHERE t1.f1 = t2.f1;
If you executed the above SQL against Oracle database, there will be a ORA-00957 error which means duplicate column name.
But the following SQL query will be executed succefully, because the view column name is specified.
CREATE VIEW v1 (t1f1, t2f1, t1f2, t2f3)
as
SELECT
t1.f1,
t2.f1,
t1.f2, t2.f3
FROM t1, t2
WHERE t1.f1 = t2.f1;
The star column (*) in the process of the column level lineage
How to handle the star column (*) during the process of the column level lineage
create view v as select * from t;
The SQL will create a view: v by using the column name in the table t.
However, without the additional metadata, the GSP doesn’t know the column name in table t.
So, use * to link the relation between view and table like this: t.* -> RS-1.* -> v.*
<relation id="1" type="fdd" effectType="select">
<target id="6" column="*" parent_id="5" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
<source id="3" column="*" parent_id="2" parent_name="t" coordinate="[1,25],[1,26]"/>
</relation>
<relation id="2" type="fdd" effectType="create_view">
<target id="9" column="*" parent_id="8" parent_name="v" coordinate="[1,25],[1,26]"/>
<source id="6" column="*" parent_id="5" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
</relation>
The GSP can do a little better if the SQL is something like this:
create view v as select * from t where column1 + column2 > 0;
The GSP will know column1 and column2 must belonged to table t, so this relation is created:
<relation id="1" type="fdd" effectType="select">
<target id="7" column="*" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
<source id="3" column="column1" parent_id="2" parent_name="t" coordinate="[1,40],[1,47]"/>
<source id="4" column="column2" parent_id="2" parent_name="t" coordinate="[1,50],[1,57]"/>
</relation>
and the resultset outputed in the select * must include column1 and column2.
<relation id="1_0" type="fdd" effectType="select">
<target id="7_0" column="column1" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
<source id="3" column="column1" parent_id="2" parent_name="t" coordinate="[1,40],[1,47]"/>
</relation>
<relation id="1_1" type="fdd" effectType="select">
<target id="7_1" column="column2" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
<source id="4" column="column2" parent_id="2" parent_name="t" coordinate="[1,50],[1,57]"/>
</relation>
Please note that the relation id is in the format of 1_index, where the index is 0,1.
This means that those columns are not really listed in the select list, but derived from the star column in the select list
whose relation id is 1.
Also, column1 and column2 listed in the view: t is derived from the star column with the following relation map.
<relation id="3_0" type="fdd" effectType="create_view">
<target id="10_0" column="column1" parent_id="9" parent_name="v" coordinate="[1,25],[1,26]"/>
<source id="7_0" column="column1" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
</relation>
<relation id="3_1" type="fdd" effectType="create_view">
<target id="10_1" column="column2" parent_id="9" parent_name="v" coordinate="[1,25],[1,26]"/>
<source id="7_1" column="column2" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
</relation>
<relation id="3" type="fdd" effectType="create_view">
<target id="10" column="*" parent_id="9" parent_name="v" coordinate="[1,25],[1,26]"/>
<source id="7" column="*" parent_id="6" parent_name="RS-1" coordinate="[1,25],[1,26]"/>
</relation>
TExpression and acceptChildren
User should be careful When use acceptChildren() method in the public void preVisit(TExpression node)
or public void postVisit(TExpression node) method of your customzied visitor class that extends TParseTreeVisitor.
class TreeVisitor extends TParseTreeVisitor {
public void preVisit(TExpression node) {
switch (node.getExpressionType()) {
case logical_and_t:
case logical_or_t:
node.getLeftOperand().acceptChildren(this);
node.getRightOperand().acceptChildren(this);
break;
default:
break;
}
}
The above code will cause the left and right sub-expression repeatedly visited, if the expression itself is deeply nested, then the performance will be impacted severely.
Since the acceptChildren() method of TExpression will iterate all sub-expression for you automatically, you shouldn’t call acceptChildren() in the preVisit() method of your own visitor. Only add your business code in the preVisit() method and let the acceptChildren() method of TExpression do the iteration for you.
If you want to iterate all sub-expression in your own code, please use accept() method instead of acceptChildren().
Below is the code of the acceptChildren() method of TExpression for your reference.
public void acceptChildren(TParseTreeVisitor v){
v.preVisit(this);
switch(expressionType){
case simple_object_name_t:
objectOperand.acceptChildren(v);
break;
case list_t:
case collection_constructor_list_t:
case collection_constructor_multiset_t:
case collection_constructor_set_t:
if (exprList != null){
for(int i=0;i<exprList.size();i++){
exprList.getExpression(i).acceptChildren(v);
}
}
break;
case function_t:
case new_structured_type_t:
case type_constructor_t:
functionCall.acceptChildren(v);
break;
case cursor_t:
case subquery_t:
case multiset_t:
subQuery.acceptChildren(v);
break;
case case_t:
caseExpression.acceptChildren(v);
break;
case pattern_matching_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
if (likeEscapeOperand != null){
likeEscapeOperand.acceptChildren(v);
}
break;
case exists_t:
subQuery.acceptChildren(v);
break;
case new_variant_type_t:
newVariantTypeArgumentList.acceptChildren(v);
break;
case unary_plus_t:
case unary_minus_t:
case unary_prior_t:
rightOperand.acceptChildren(v);
break;
case arithmetic_plus_t:
case arithmetic_minus_t:
case arithmetic_times_t:
case arithmetic_divide_t:
case power_t:
case range_t:
case concatenate_t:
case period_ldiff_t:
case period_rdiff_t:
case period_p_intersect_t:
case period_p_normalize_t:
case contains_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case assignment_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case sqlserver_proprietary_column_alias_t:
rightOperand.acceptChildren(v);
break;
case arithmetic_modulo_t:
case bitwise_exclusive_or_t:
case bitwise_or_t:
case bitwise_and_t:
case bitwise_xor_t:
case exponentiate_t:
case scope_resolution_t:
case at_time_zone_t:
case member_of_t:
case arithmetic_exponentiation_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case at_local_t:
case day_to_second_t:
case year_to_month_t:
leftOperand.acceptChildren(v);
break;
case parenthesis_t:
leftOperand.acceptChildren(v);
break;
case simple_comparison_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case group_comparison_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case in_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case floating_point_t:
leftOperand.acceptChildren(v);
break;
case logical_and_t:
case logical_or_t:
case logical_xor_t:
case is_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case logical_not_t:
rightOperand.acceptChildren(v);
break;
case null_t:
leftOperand.acceptChildren(v);
break;
case between_t:
if (betweenOperand != null){
betweenOperand.acceptChildren(v);
}
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case is_of_type_t:
leftOperand.acceptChildren(v);
break;
case collate_t: //sql server,postgresql
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case left_join_t:
case right_join_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case ref_arrow_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case typecast_t:
leftOperand.acceptChildren(v);
break;
case arrayaccess_t:
arrayAccess.acceptChildren(v);
break;
case unary_connect_by_root_t:
rightOperand.acceptChildren(v);
break;
case interval_t:
intervalExpr.acceptChildren(v);
break;
case unary_binary_operator_t:
rightOperand.acceptChildren(v);
break;
case left_shift_t:
case right_shift_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case array_constructor_t:
if (subQuery != null){
subQuery.acceptChildren(v);
}else if (exprList != null){
exprList.acceptChildren(v);
}else if (arrayConstruct != null){
arrayConstruct.acceptChildren(v);
}
break;
case row_constructor_t:
if (exprList != null){
exprList.acceptChildren(v);
}
break;
case unary_squareroot_t:
case unary_cuberoot_t:
case unary_factorialprefix_t:
case unary_absolutevalue_t:
case unary_bitwise_not_t:
getRightOperand().acceptChildren(v);
break;
case unary_factorial_t:
getLeftOperand().acceptChildren(v);
break;
case bitwise_shift_left_t:
case bitwise_shift_right_t:
getLeftOperand().acceptChildren(v);
getRightOperand().acceptChildren(v);
break;
case multiset_union_t:
case multiset_union_distinct_t:
case multiset_intersect_t:
case multiset_intersect_distinct_t:
case multiset_except_t:
case multiset_except_distinct_t:
getLeftOperand().acceptChildren(v);
getRightOperand().acceptChildren(v);
break;
case json_get_text:
case json_get_text_at_path:
case json_get_object:
case json_get_object_at_path:
case json_left_contain:
case json_right_contain:
case json_exist:
case json_any_exist:
case json_all_exist:
getLeftOperand().acceptChildren(v);
getRightOperand().acceptChildren(v);
break;
case interpolate_previous_value_t:
getLeftOperand().acceptChildren(v);
getRightOperand().acceptChildren(v);
break;
case submultiset_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case overlaps_t:
leftOperand.acceptChildren(v);
rightOperand.acceptChildren(v);
break;
case is_a_set_t:
leftOperand.acceptChildren(v);
break;
case array_t:
if (getExprList() != null){
getExprList().acceptChildren(v);
}
break;
default:;
}
v.postVisit(this);
}
2019
Dotnet Parser Throws Exception
General SQL Parser .NET version
We have have confirmed, that the issue appears strictly only with .NET framework 4.6.1586.0, but happens just sometimes.
With the higher .NET framework 4.7.2053.0 all works fine.
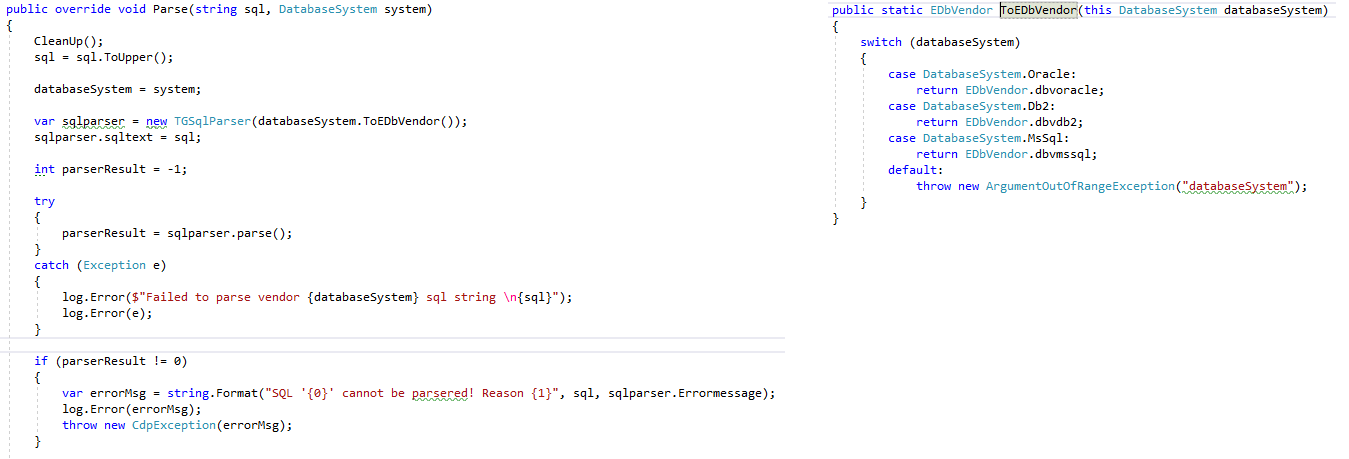
2019-10-02 14:02:56,506 ERROR [11] ParserBase:0 Failed to parse vendor MsSql sql string
CREATE TABLE COPS_ZT (
REC_ID BIGINT IDENTITY NOT NULL,
REF_REC_ID BIGINT NOT NULL,
REC_DATE DATETIME2 NOT NULL,
REC_STATUS NUMERIC NOT NULL,
REC_ERROR NVARCHAR(255),
ZT_CREATION_USER NVARCHAR(255),
ZT_CREATION_DATE DATETIME2)
2019-10-02 14:02:56,513 ERROR [11] ParserBase:0 System.ArgumentException: Destination array was not long enough. Check destIndex and length, and the array's lower bounds.
at System.Array.Copy(Array sourceArray, Int32 sourceIndex, Array destinationArray, Int32 destinationIndex, Int32 length, Boolean reliable)
at System.Collections.Generic.Dictionary`2.Resize(Int32 newSize, Boolean forceNewHashCodes)
at System.Collections.Generic.Dictionary`2.Insert(TKey key, TValue value, Boolean add)
at gudusoft.gsqlparser.nodes.TTypeName.searchTypeByName(String typenameStr)
at gudusoft.gsqlparser.nodes.TTypeName.set_DataTypeByToken(TSourceToken value)
at gudusoft.gsqlparser.nodes.TTypeName.setDataTypeInTokens()
at gudusoft.gsqlparser.TParserMssqlSql.yyaction(Int32 yyruleno)
at gudusoft.gsqlparser.TParserMssqlSql.yyparse()
at gudusoft.gsqlparser.TCustomSqlStatement.dochecksyntax(TCustomSqlStatement psql)
at gudusoft.gsqlparser.TCustomSqlStatement.parsestatement(TCustomSqlStatement pparentsql, Boolean isparsetreeavailable)
at gudusoft.gsqlparser.TGSqlParser.doparse()
at CopsDatabasePatcher.SqlParser.SqlParser.Parse(String sql, DatabaseSystem system)
2019-10-02 14:02:56,522 ERROR [11] ParserBase:0 SQL 'CREATE TABLE COPS_ZT (
REC_ID BIGINT IDENTITY NOT NULL,
REF_REC_ID BIGINT NOT NULL,
REC_DATE DATETIME2 NOT NULL,
REC_STATUS NUMERIC NOT NULL,
REC_ERROR NVARCHAR(255),
ZT_CREATION_USER NVARCHAR(255),
ZT_CREATION_DATE DATETIME2)' cannot be parsered! Reason
Code to produce this error:
2018
General SQL Parser Java version 1.9.5.5 released (2018-10-22)
- GSP Java version 1.9.5.5(2018-10-21)
- [Oracle] able to recognize and parser noneditionable trigger
- [Teradata] support at time zone clause of DATE datatype.
- [Teradata] support with return only clause in declare cursor statement.
- [SQL Server] support OBJECT:: in grant statement.
- [SQL Server] support xmlnamespaces clause used together with CTE.
General SQL Parser dotnet version 3.2.7.2 released (2018-10-22)
- dotnet version 3.2.7.2(2018-10-21)
- [SQL Server] support NO_PERFORMANCE_SPOOL, MIN_GRANT_PERCENT, HINT_MAX_GRANT_PERCENT
- [API] add new enum elements: EQueryHint.E_QUERY_HINT_NO_PERFORMANCE_SPOOL, E_QUERY_HINT_MIN_GRANT_PERCENT, E_QUERY_HINT_MAX_GRANT_PERCENT
- [SQL Server/scriptWriter] support call target expression of function call.
- [Oracle] able to recognize create or repleace context statement.
- [DB2] able to link column in call statement to table of create trigger statement.
- dotnet version 3.2.7.1(2018-10-09)
- [SQL Server] Doesn’t treat [DATE] as a regular column name.
- dotnet version 3.2.7.1(2018-10-08)
- [API] TTypeName.isCharUnit(), TTypeName.ByteUnit is no longer used, replaced by TTypeName.charUnitToken
- [Oracle] able to get label name after loop/while statement.
- [Oracle] support on null clause in default clause.
- [API] add new property: TColumnDefinition.onNull
- dotnet version 3.2.7.0(2018-10-08)
- [sql formatter] Able to format subquery or CASE statement inside of CAST function.
- dotnet version 3.2.6.9(2018-10-03)
- [API] add new property: TColumnDefinition.persistedColumn.
- [SQL Server] able to get persisted information from column definition.
- [API] add new property: TColumnDefinition.filestream.
- [SQL Server] support FILESTREAM keyword in create table.
- [API] add new property: TColumnDefinition.sparseColumn.
- [SQL Server] Able to get SPARSE column information from TColumnDefinition.
- dotnet version 3.2.6.8(2018-09-28)
- [MySQL] Able to get comment/KEY_BLOCK_SIZE/parser name index option in MySQL create index statement.
- [API] TMySQLIndexOption.indexOptionType
- [API] add new enum: EIndexOptionType
- [API] add new property : TCreateIndexSqlStatement.IndexOptionList to access index option of MySQL create index statement.
- [SQL Server] able to fetch include column list from create index statement.
General SQL Parser Java version 1.9.4.4 released (2018-08-22)
- GSP Java version 1.9.4.4(2018-08-22)
- [API] Add new method TSourceToken TSourceToken.nextSolidToken(boolean treatCommentAsSolidToken)
- [API] Add new method TSourceToken TSourceToken.prevSolidToken(boolean treatCommentAsSolidToken)
General SQL Parser Java version changelog 2018-08-01
version history of general sql parser:
- GSP Java version 1.9.4.4(2018-08-22)
- [API] Add new method TSourceToken TSourceToken.nextSolidToken(boolean treatCommentAsSolidToken)
- [API] Add new method TSourceToken TSourceToken.prevSolidToken(boolean treatCommentAsSolidToken)
General SQL Parser .NET version changelog 2018-08-01
- dotnet version 3.2.5.6(2018-08-01)
- [Oracle] fix a bug can’t parse plsql block not ended by a semicolon.
- [general] avoid System.ArgumentNullException when call isvalidsqlpluscmd().
- dotnet version 3.2.5.6(2018-07-27)
- [scriptWriter] fix a bug when new TObjectName with object and part source token.
- [API] add new method: TSourceToken.toScript()