本文目的是帮助用户掌握:通过操作 SQL 语句的 AST,输出新的 SQL 语句。具体而言, 是通过调用 TParseTreeNode.toString() 方法(拼接对应的 token list)来输出 SQL 语句。使用这种方法,只要是 GSP 能够解析的 SQL, 都可以正确输出 SQL 语句。这种方法的使用场景是: 解析 SQL 语句, 修改 SQL 对应的 AST, 输出新的 SQL 语句。
GSP 中另一个输出 SQL 语句的方法是 TParseTreeNode.toScript() , 它根据语法把 AST 中每个 node 转换为文本, 然后拼接成完整的 SQL 语句。主要的使用场景是:用户完全从头开始利用 GSP API 来构造一颗 SQL 语句的 AST 树,然后根据 AST 来输出 SQL 语句。 当然也可以利用 TParseTreeNode.toScript() 来输出 GSP 解析后的 SQL 语句,但如果 AST 中某个 node 转换文本功能没有支持,则整个 SQL 语句的输出将失败。
一、 SQL 文本,AST Node 及 Tokens 的关系
GSP 解析 SQL 语句,先由 lexer 把 SQL 文本分解成一系列 tokens, 然后由 parser 逐个处理这些 tokens, 生成语法树(AST)。AST 中的每个 node 对应 SQL 语句中的一部分文本,也对应 tokens 中的一段连续的 tokens.
SELECT emp_id,salary+100 FROM emp
以上SQL对应下面的 token list:

每个 node 都含有一个起始 token(startToken) 和一个结束 token(endToken)。组成 node 的 token 由 startToken 开始,到 endToken 结束。node 中的所有 token 以双向链表方式建立关联。
public TSourceToken getStartToken()
public TSourceToken getEndToken()
由 SQL 的语法决定, 一个 token 可以是一个或多个 node 的 startToken, 也可以是一个或多个 node 的 endToken.
public Stack<TParseTreeNode> getNodesStartFromThisToken()
public Stack<TParseTreeNode> getNodesEndWithThisToken()
例 1, token: emp_id
以它为 startToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:emp_id
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:emp_id
2: Node type:gudusoft.gsqlparser.nodes.TResultColumn, Node text:emp_id
以它为 endToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:emp_id
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:emp_id
2: Node type:gudusoft.gsqlparser.nodes.TResultColumn, Node text:emp_id
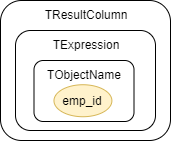
可以发现,当 node 只有唯一一个 token 组成时, node 的 startToken 和 endToken 都为该 token。
例 2, token: salary
以它为 startToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:salary
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:salary
2: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:salary+100
3: Node type:gudusoft.gsqlparser.nodes.TResultColumn, Node text:salary+100
以它为 endToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:salary
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:salary
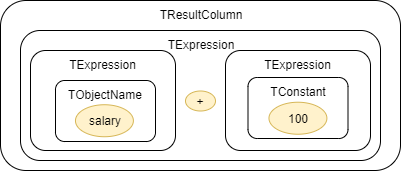
例 3, token: 100
以它为 startToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TConstant, Node text:100
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:100
以它为 endToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TConstant, Node text:100
1: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:100
2: Node type:gudusoft.gsqlparser.nodes.TExpression, Node text:salary+100
3: Node type:gudusoft.gsqlparser.nodes.TResultColumn, Node text:salary+100
例 4, token: emp
Parser 以 LALR 的方式解析 SQL,因此以某个 token 开始的所有 node 被 parser 以创建的先后次序依次存放在栈中, 即子 node 比父 node 先进入栈中。但在 LALR 解析的前期或后期,以这个 token 为 startToken 或 endToken 的 node 可能还会被创建,因此在栈高层的 node 并不一定 都是底层 node 的父辈 node。 判断栈中两个 node 的包含关系, 通过比较它们包含 token 个数来决定, token 个数多的为父辈 node。
从 emp token 我们就可以观察到这种现象,特别是以它为 endToken 的 node。
以它为 startToken 的 node 有:
0: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:emp
1: Node type:gudusoft.gsqlparser.nodes.TFromTable, Node text:emp
2: Node type:gudusoft.gsqlparser.nodes.TTable, Node text:emp
3: Node type:gudusoft.gsqlparser.nodes.TJoin, Node text:emp
以它为 endToken 的 node 有:
0: Node type:gudusoft.gsqlparser.stmt.TSelectSqlStatement, Node text:SELECT emp_id,salary+100 FROM emp
1: Node type:gudusoft.gsqlparser.nodes.TObjectName, Node text:emp
2: Node type:gudusoft.gsqlparser.nodes.TFromTable, Node text:emp
3: Node type:gudusoft.gsqlparser.nodes.TSelectSqlNode, Node text:SELECT emp_id,salary+100 FROM emp
4: Node type:gudusoft.gsqlparser.nodes.TTable, Node text:emp
5: Node type:gudusoft.gsqlparser.nodes.TJoin, Node text:emp
其中, node0 是在 getrawsqlstatements() 时创建的。 node1, node2, node3 是在 Parser 以 LALR 的方式解析时创建的。 node4, node5 是在后期的语义处理阶段创建的。
1, TParseTreeNodeList 子类类型的 node
TParseTreeNodeList 子类类型的 node 维护着一个链表, 该链表包含多个相同类型的 node. TParseTreeNodeList 类型的 node 本身不直接包含 startToken 和 endToken。它的 startToken 为它链表中首个 node 的 startToken. 它的 endToken 为它链表中最后一个 node 的 endToken.
以 TParseTreeNodeList 子类 TResultColumnList 为例,TSelectSqlStatement.getResultColumnList() 返回下面 SELECT 语句的 emp_id,salary+100 部分。
SELECT emp_id,salary+100 FROM emp
因此, 该 TResultColumnList 的 startToken 为 emp_id, endToken 为 100, 同时从例1 和 例3 我们也可以知道, 以 emp_id 为 startToken 的 node 中并不包含 TResultColumnList, 以 100 为 endToken 的 node 中也不包含 TResultColumnList。
调用 node 的ToString()方法,即从 startToken 开始输出文本,遍历每一个 token,直到 endToken 结束。因此,使用 GSP 的 API 对 AST node 进行操作时,更新 node 结构也会同步跟新对应的 token,以保证 node 的 ToString() 输出正确的文本。
2, 节点与子节点的关系
语法树 (AST) 包含多个节点 (node),同时,节点 (node) 也可以包含多个子节点,因此,一个顶级的 node 就是一颗语法树。例如TSelectSqlStatement.
不同数据库的相同 SQL 语句,例如 SELECT 语句,在 GSP 中用同一个节点 TSelectSqlStatement 表示,它的子节点因为不同的数据库而可能会有不同,例如,Oracle 中就没有 TTopClause 这个子节点。visitor 访问代表不同数据库 SELECT 语句的 TSelectSqlStatement 节点的方式是相同的。
节点可以包含多个子节点,同级子节点对应的 token list 不会重叠,节点的 token list 包含所有子节点的 token list,除此之外,可能还会包含节点自身独有的辅助 token,例如,TSelectSqlStatement 就有 SELECT 这个token,它不属于任何子节点。
节点的 startToken, endToken 可能和它子节点的startToken, endToken重合,分为三种情况:
- 节点和子节点的 startToken, endToken 都重合。
- 节点和子节点的 startToken 重合, 但节点的 endToken 在子节点的 endToken 之后。
- 节点和子节点的 endToken 重合, 但节点的 startToken 在子节点的 startToken 之前。
因此,当某个节点的 startToken, endToken 发生变化时,共用这些 startToken, endToken 的节点也需要同步更新他们 startToken, endToken 的指向。
二、GSP 如何保证 AST Node 和 Tokens 的同步
这个 SQL 表达式
fx(2)+1
它的 token list 为:

它的 node 关系图:
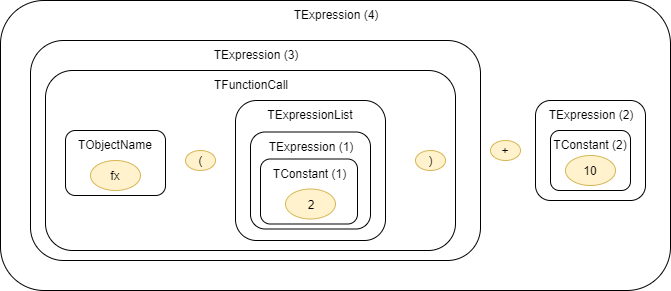
从图中可以知道,fx 同时是 TObjectName, TFunctionCall, TExpression (3), TExpression (4) 的 startToken.
当我们用 TFunctionCall.setString('gx(2)') 把 fx(2) 更改为 gx(2) 时,子节点 TFunctionCall 的 startToken 变为 gx, 此时如果不做同步,其它三个节点的 startToken 仍然指向 fx,这是不对的。此时如果调用 TExpression (3).toString() , 它的结果是 fx(2), 而不是已经变更后的 gx(2).
有一点需要注意的是,如果从更高层级的node调用toString()方法,输出结果仍然是正确的,例如:
WHERE fx(2)+1>1
当用TFunctionCall.setString('gx(2)')把fx(2)更改为gx(2)后,TWhereClause.toString() 仍将输出正确的结果,原因是:
TFunctionCall.setString()不会影响TWhereClause的startToken,它仍然是WHERE。- 在
TFunctionCall.setString()时,gx会取代fx加入到TWhereClause的token list中来。
接下来, 我们主要讨论在修改 AST 的同时, 为了保证 node 和 token list 的同步, GSP 提供了哪些数据结构, 并且在利用 API 对 AST 进行操作时, 如何保证 node 和 token list 的同步。
1、 保证 AST Node 和 Tokens 同步的数据结构
// TParseTreeNode:
public TSourceToken getStartToken()
public TSourceToken getEndToken()
public void setStartToken(TSourceToken newStartToken)
public void setEndToken(TSourceToken newEndToken)
public void removeTokens() // 从链表中移除该 node 对应的所有 token, 并确保 node 和 startToken, endToken状态的准确
public void appendNewNode(TParseTreeNode newNode, boolean needCommaBefore)
public void replaceWithNewNode(TParseTreeNode newNode)
public void setText(String nodeText)
public void setNewSubNode( TParseTreeNode oldSubNode, TParseTreeNode newSubNode,TParseTreeNode anchorNode)
public void setAnchorNode(TParseTreeNode anchorNode)
public ENodeStatus getNodeStatus()
设置 node 的 startToken, endToken
public void setStartToken(TSourceToken newStartToken)
设置 node 的 startToken。如果该 node 原来已经有一个 startToken, 并且该 node 在原有 startToken 所维护的 NodesStartFromThisToken 栈的顶部, 那么把该 node 从原有 token 的 NodesStartFromThisToken 栈中弹出。然后检查 node 是否在新 token 的 NodesStartFromThisToken 中存在, 如果不存在, 压入该 node。
以上我们可以看出, 设置一个 node 的 startToken, 需同时维护 node 和 token 的双向关系。
public void setEndToken(TSourceToken newStartToken)
setEndToken() 的处理逻辑同 setStartToken()。
// TSourceToken:
public Stack<TParseTreeNode> getNodesStartFromThisToken()
public Stack<TParseTreeNode> getNodesEndWithThisToken()
// 双向链表中, 通过以下方法把 token 加入链表,或从链表中移除。
public TSourceToken getNextTokenInChain()
public void setNextTokenInChain(TSourceToken nextTokenInChain)
public TSourceToken getPrevTokenInChain()
public void setPrevTokenInChain(TSourceToken prevTokenInChain)
public void removeFromChain()
利用 API 对 AST 进行操作后, 利用以上数据结构和方法, 同步 node 和 token list。主要实现这三个功能:
- 在 token 双向链表中, 在指定的位置,把一个或多个 token 加入链表,或从链表中更新、移除。
- token 被更新、移除后, 把该 token 作为 startToken 或 endToken 的 node 做更新。
- node 被更新、移除后,它本身及子 node 的状态需要做更新,确保后续操作可以知道这些 node 所处的状态, 并作出合适的处理。
首次建立 token 间的双向链接
TGSqlParser parse SQL 语句时,所有 token 在 dosqltexttotokenlist() 中首次建立双向链接。
2、 利用 API 对 AST 进行的操作
2.1 TParseTreeNode setString()
给 node 设置 text 时,GSP 会把 text 转换成 tokens, 然后把该 node 原来在 AST 的 token list 中的 token 用这些新的 token 取代。node 及子 node 的结构并没有发生变化。
- 把该 node 及子 node 的 nodeStatus 更新为 nsPartitial 或 nsDetached
- 更新和该 node 指向相同 startToken, endToken 父节点的 startToken, endToken
- 在 AST 的 token 链表中,把该 node 原有的 token 换成新的 token
SELECT *
FROM scott.employee
WHERE e.job_id = 1
sqlparser.sqltext = "SELECT *\n" +
"FROM scott.employee\n" +
"WHERE e.job_id = 1";
sqlparser.parse();
TSelectSqlStatement select = (TSelectSqlStatement)sqlparser.sqlstatements.get(0);
TWhereClause whereClause = select.getWhereClause();
whereClause.getCondition().setString("e.salary > 1000");
System.out.println(select.toString());
执行上面Java代码后,SQL语句为:
SELECT *
FROM scott.employee
WHERE e.salary > 1000
如果需要删除该节点, 请在父节点中调用 setXXX(null) 方法。 调用 setString() 时传入一个长度为 0 的空字符串不起作用。
因为每种数据库的词法有差别,在把text转换成tokens时,需要明确是哪种数据库。为避免每次调用
setString()时都额外指定数据库,引入一个静态全局变:TGSqlParser.currentDBVendor,当创建新的TGSqlParser实例时,设置TGSqlParser.currentDBVendor的值,该值总是和最近一次创建的TGSqlParser实例的数据库相同。如果想改变下一次setString()使用的数据库词法,可以更改该值。在多线程环境中这个设计可能导致问题
2.2 删除 node
一 、 调用父节点 setXXX() 方法, 并且传入一个 null 参数,即把该 node 从父节点从删除。 GSP 的内部具体实现如下:
- 调用
TParseTreeNode.removeTokens()把对应的 tokens 从 AST 的 token list 中删除。 - 为保证
toString()生成的 SQL 语法的正确,可能需要删除该 node 前后的一些辅助token。尤其是TParseTreeNodeList删除其中的某个元素时。 - 在父节点中把指向该 node 的引用设为 null。
二、 TParseTreeNodeList 的子类节点移除其中的某个元素时,调用 removeItem(int index), 它会自动调用 removeAndSyncTokens(int index),如果被移除元素是 list 中的第一个节点,并且它之后有 comma token , 该 comma token 会被一起移除。
如果被移除元素不是 list 中的第一个节点,它之前有 comma token 时, 需要一起移除。
以该SQL为例
SELECT e.emp_id,e.fname,e.lname,j.job_desc
FROM scott.employee AS e,jobs AS j
如果要从select list中删除e.emp_id, 则e.emp_id后面的,也必须一起删除。而删除j.job_desc时,则j.job_desc之前的,也必须一起删除。
2.3 更新 node
调用父节点 setXXX() 方法设置新的 node。 这种情况一般建议使用原有 node 的 setString() 方法,效果是一样的,执行效率更高。
TGSqlParser parser = new TGSqlParser(EDbVendor.dbvoracle);
parser.sqltext = "SELECT A.COLUMN1, B.COLUMN2 from TABLE1 A, TABLE2 B where A.COLUMN1=B.COLUMN1";
parser.parse();
TSelectSqlStatement select = (TSelectSqlStatement)parser.sqlstatements.get(0);
//create a new node
TWhereClause whereClause = new TWhereClause();
whereClause.setText("where a>2");
//replace with the new created node
select.setWhereClause(whereClause);
System.out.println (select.toString());
2.4 新增 node
父节点中原来指向该节点的指针为空, 新增 node 需要在父节点中调用对应的 setXXX() 方法。
例如这个 SELECT 语句, TCustomSqlStatement.getWhereClause() 是空的。
SELECT emp_id,salary+100 FROM emp
为给该语句增加 where clause, 我们可以这样:
//create a new node
TWhereClause whereClause = new TWhereClause();
whereClause.setText("where a>2");
//link this new created node in the SELECT statement
select.setWhereClause(whereClause);
这样,我们就可以得到这个新的 SELECT 语句:
SELECT emp_id,salary+100 FROM emp where a>2
增加node时,一般包含以下步骤:
- 创建该node,
new TParseTreeNode(), 然后调用TParseTreeNode.setString()设置该 node 的文本. - 在父节点调用
setXXX(TParseTreeNode)方法, 并传入TParseTreeNode参数.
确定插入位置
在 GSP 的内部, 需要在 AST 的 token list 中找到合适的位置 插入该 node 的 token。以上面的 SQL 为例, 需要找到 emp token, 然后在它后面把新的 token 插入。
我们以 TWhereClause 为例, 在 TCustomSqlStatement 中,
public void setWhereClause(TWhereClause newWhereClause)
当使用这个方法时, token 的插入点默认为父节点的最后一个 token, 例如上面的 SQL 的例子。但有时,这种假设会产生不正确的结果。例如这个语句:
SELECT emp_id,salary+100 FROM emp order by 1
如果还是使用 setWhereClause(TWhereClause newWhereClause), 那将产生下面错误的 SQL 语句。
SELECT emp_id,salary+100 FROM emp order by 1 where a>2
因为 SQL 语句的灵活性, GSP 无法自己辨别该把新 node 的 token 插入到哪个位置,因此,TParseTreeNode 提供这个方法,由调用者决定插入位置。
public void setAnchorNode(TParseTreeNode anchorNode)
TParseTreeNode anchorNode 是和新 node 同级的node,并且在 AST 中已经存在。针对上例中的 SQL, 我们可以这样
select.setAnchorNode(select.joins);
select.setWhereClause(whereClause);
这样 where clause 为被插入到 anchor node: joins (即 from clause) 后, 得到以下正确的结果:
SELECT emp_id,salary+100 FROM emp where a>2 order by 1
添加可能需要的辅助 token
- 可能需要添加辅助token,以保证SQL语法的正确。(尚未有具体的实现)
TParseTreeNodeList.addElement(T ptn)插入子节点时,会对需要添加的辅助 token 做统一处理。
以该SQL为例
SELECT e.emp_id,e.fname,e.lname
FROM scott.employee AS e,jobs AS j
当在e.lname后加入j.job_desc时,必须在j.job_desc前同时加入,以确保语法正确。
3、GSP 中目前实现的对 AST 进行操作的 API
对 AST 进行的操作就是对 node 的新增、删除和更新(更新 node 自身,或更新 node 的文本)。
GSP API 已经完全支持 node 的删除和更新,但新增功能因为不同的 node 需要单独的 setXXX() 方法,需逐步添加支持,目前实现以下方法:
- TParseTreeNode.setString(String sqlSegment), 更新 node 文本。
- TParseTreeNodeList.removeItem(int index), 删除 node
- TCustomSqlStatement.setWhereClause()
- 所有 TSelectSqlStatement.setXXX() 方法
利用visitor来访问和修改node
利用 visitor 来找到指定类型的 node 是一种高效的方法。利用 visitor 遍历整颗语法树并对 node 进行操作时,需要注意以下几点:
- 最小化原则,能够修改某个特定子节点,就不要修改整个父节点。同级节点的修改不会互相影响。
- 当用
setString()修改某个节点后,它及其所有子节点都不再处于ENodeStatus.nsNormal状态,即不再属于整颗语法树,随后对这些子节点的改动也是无效的,不会反应在语法树中。 - 在 visitor 的
postVisit()中处理节点时,可以保证先让子节点得到处理。 - 一个 visitor 可以根据实际业务需求,多次遍历同一个 node,处理不同的子节点。但要注意处理的节点必须处于
ENodeStatus.nsNormal状态,否则改动不会反应到最后toString()的结果中。
在把一颗代表Oracle的SELECT语句的TSelectSqlStatement语法树转换成代表SQL Server的SELECT语句的TSelectSqlStatement时,我们可以采用上述方法。转换完成后,利用toString()就可以输出一个满足SQL Server语法的SELECT语句。
输出修改 AST 后的 SQL 语句: Node toString()
增、删、改node时,node 的 token list 已经同步到整个 AST 中,那么,输出整个 SQL 语句的文本只要简单的 遍历 startToken 到 endToken 即可。
Node toScript()
从上面的介绍可知,利用toString()从语法树生成SQL文本时,对语法树上node做改动时,必须对底层对应的token做好同步。
利用toScript()从语法树生成SQL文本时,对语法树上node做改动,无需对底层对应的token做同步,但对语句中
的每一个node都要根据语法重新生成文本,即便这个node在本次操作中没有发生变化。由于GSP目前无法对所有的SQL
语法都支持重新生成文本,因此容易导致生成不正确的SQL文本。
toScript()的优点在于改动语法树中的node时,无需同步更新底层的对应token,特别是一些辅助token。
Token的基本信息
1. token的类型
public ETokenType tokentype
主要的类型有:
ttkeyword, 上例中的SELECT,SELECT,FROM,WHERE,ORDER,BY。ttidentifier,上例中的e,emp_id等。ttwhitespace, 空格和tab。ttreturn,换行符。- 各种符号,
ttperiod,ttcomma等。 ttsimplecomment,ttbracketedcomment,注释。
2. token的code
public int tokencode
code用来表示token的编号。ttkeyword类型的token有唯一不同的编号。ttidentifier类型的token编号值相同,都为264。各种符号的编号就是它们的ASCII值。
3. token的text
token的文本。
Node
Node表示SQL语法中的各个元素,例如
- 数据库对象名,
e.emp_id,它包含三个tokene,.,emp_id。 - 也可以是一个子句(clause),例如where子句,
WHERE e.job_id = j.job_id,它包含ttkeyword,ttwhitespace,符号,ttidentifier等token。 - 也可以是一个语句,例如SELECT,包含各种SQL子句。